
How the Human Genome Project revolutionized understanding of our DNA
https://ift.tt/5zTwByk
In October 1990, biologists officially embarked on one of the century’s most ambitious scientific efforts: reading the 3 billion pairs of genetic subunits — the A’s, T’s, C’s and G’s — that make up the human instruction book.
The project promised to blow open our understanding of basic biology, reveal relationships between the myriad forms of life on the planet and transform medicine through insights into genetic diseases and potential cures. When the project was completed in 2003, the scientists having read essentially every letter, President Bill Clinton called it a “stunning and humbling achievement” and predicted it would “revolutionize the diagnosis, prevention and treatment of most, if not all, human diseases.”
Even dreaming up such an endeavor depended on decades of previous discoveries. In 1905, English biologist William Bateson, who championed the work of Austrian monk Gregor Mendel, suggested the term genetics for a new field of study focused on heredity and variation. Early the next decade, American biologist Thomas Hunt Morgan and his colleagues showed that genes are carried on chromosomes. Biochemists had been studying DNA for nearly three-quarters of a century when Oswald Avery and his team at the Rockefeller Institute in New York City helped establish in the 1940s that DNA is the genetic material. And perhaps most notable, and famous today, is the 1953 discovery of the double-helix structure of DNA, by James Watson and Francis Crick of the University of Cambridge and Rosalind Franklin and Maurice Wilkins of King’s College London.
To celebrate our 100th anniversary, we’re highlighting some of the biggest advances in science over the last century. To see more from the series, visit Century of Science.
But when the draft of the genetic instruction book was first published, independently by an international collective of academic and government labs called the Human Genome Project and the private company Celera Genomics, led by J. Craig Venter, the text was “as striking for what we don’t see as for what we do,” Science News reported (SN: 2/17/01, p. 100). There were many fewer genes than expected, leaving a puzzle about what all the remaining DNA was for.
In the decades since, scientists have filled in some of that puzzle — identifying a host of genes, for example, that don’t make proteins but are still essential in the body. Other researchers have searched the instruction book to find new treatments for diseases and to figure out how we’re all related — not just people, but all life on planet Earth, past and present.
To explore how far our understanding of our DNA has come, Science News senior writer and molecular biology reporter Tina Hesman Saey talked with Eric Green, director of the National Human Genome Research Institute at the National Institutes of Health in Bethesda, Md. Green got his start in genomics in the lab of Maynard Olson at Washington University in St. Louis, a pioneer in the field. At the same time, Saey was a graduate student in molecular genetics, working down the hall. She remembers as an undergraduate student sequencing the genes of bacteria 50 to 100 chemical subunits, or bases, at a time. “My mind was completely blown by the idea that you could put together 3 billion bases.” The conversation that follows, which has been edited for length and clarity, looks back on the project and ahead to all that’s left to learn. — Elizabeth Quill


Ambitious beginnings
Saey: My first memory of the Human Genome Project was when I was an undergraduate student at the University of Nebraska in Lincoln, and I remember Walter Gilbert, who is a Nobel Prize winner, coming and talking about the project. He proposed this really audacious idea of sequencing 3 billion pairs of bases in the human genome — all of our DNA. After Gilbert’s talk, I walked back to the lab with a couple of professors, and they were saying, “This can never happen. It’s going to cost way too much money. There’s just no way we can do this.” So how did you pull it off?
Green: By the time the genome project started in October of 1990, I was working in a cutting-edge genomics lab at Washington University. We were one of the first funded groups to participate in the Human Genome Project. We had some ideas on how to start, and we had really no idea how we were going to pull it off.
It was the overwhelmingly compelling vision for why this was so important that galvanized enthusiasm among not only a group of scientists like myself, but also the funding agencies, the governments, the private funders from around the world, who said, “This seems unimaginable, like putting a person on the moon, but it seems so important. We’ll figure it out.” So it was one of these circumstances where you just get the right people in the right place, get them resourced, get them organized, be willing to do things differently, and then figure it out as you go.
Saey: I got to witness this because I was a graduate student at Washington University, in a lab sequencing the yeast genome. Robert Waterston’s lab, which received one of the first grants from the Human Genome Project, was right across the hall. They started with C. elegans, the roundworm genome. I remember they were starting very methodically, mapping out the genes and then sequencing each piece, marching along. But then, toward the end of the ’90s, there was this shotgun sequencing revolution spearheaded by kind of a controversial figure, Craig Venter. You just shred the genome, throw it all in a sequencing machine and then put it together in the computer. Did that help a lot?
Green: There’s no question it sped things up. What Craig successfully did was to determine that there were approaches that could be used where you didn’t have to do piecemeal sequencing. The important nuance to point out is the only way you’re able to put [the pieces] back together then was by having many mapping elements that allow you to hang pieces together and organize them. It’s not like it all zipped together 3 billion letters. A lot of the meticulous mapping that had been done, painstaking mapping, helped provide organizing guideposts.
The press covered it as a race, and the press covered it as option A versus option B. And the truth resided somewhere in between. What was driving the change, of course, was technology advances. If you chart the time since the end of the Human Genome Project, it’s the same phenomenon. Every single time there’s a technology surge, you find yourself doing things completely different than the way you used to.
Saey: Technology has come a very long way from what I was doing. You can sequence thousands of bases at a time now.
Green: The other part of the story that sometimes doesn’t get told: It’s not even just the laboratory bench–based technologies. It’s also the computational technologies. Some people don’t realize that when the Human Genome Project started, there was not really a widely functional internet. I was just barely starting to use e-mail.
So here it was, we were one of the first funded groups for the Human Genome Project. We were considered state of the art. We were collaborating with an outside group generating some sequences, and the only practical way for my collaborator to get me the 300 to 400 bases of sequence was to handwrite it on a piece of paper and fax it to me. And I would analyze it by eye. It’s just remarkable that that was where we were when the project started.

Garbage to gold mine
Saey: In 2000 was the big press conference to announce the rough draft of the human genome. I was just starting my journalism career at the St. Louis Post-Dispatch, and reported on this. At that time, it was a big revelation that there were these big deserts in between genes, and that we didn’t have nearly as many genes as we thought we were going to. Humans are such complex organisms, how could we not have many more genes than a fruit fly, or a worm? That just didn’t make sense.
But now, I think, we are getting a better understanding, largely because of the way we can analyze the genome. Can you talk about how that evolution in thinking has progressed?
Green: Before the genome project started, some [people] were quite critical, and really said it was a bad idea. Some argued that it was a waste of time to sequence the genome end to end; we should just focus and sequence the genes, as if all of humans’ biological richness was going to reside in the genes. Thank goodness we didn’t listen to those critics. Because if we would have done the shortcut and only focused on the genes, we would have only skimmed the biological complexity of humans.
What we’ve come to learn is that while only 1.5 percent of the letters of the human genome directly encode for what are classically known as protein-coding genes — DNA that gets made into RNA, which gets made into protein — there’s a much larger fraction of the human genome that is biologically important and evolutionarily conserved. It’s widened our definition of a gene, because we now know that sometimes DNA may make RNA, and RNA may go off and do all sorts of biological things.
Then there’s a whole set of sequences that are far more plentiful than gene sequences, that are really doing all the choreography in our genomes in terms of determining when, where and how much genes get turned on, in what cells and what tissues, at what developmental stages, under what conditions, and so on and so forth.
It pushed us to think about all the other biological functions in DNA outside the genes. And as you accurately point out, we don’t really have a rulebook for that. And thank goodness the computer technology is helping us because the human eye would just fail miserably at figuring this out. And so as much as anything, computational biology, bioinformatics, data science are the dominant research tools to help bring clarity as to how noncoding sequences in the human genome function. And how they do that in a very carefully crafted choreography with the genes.

JOYCE NALTCHAYAN/AFP via Getty Images
Saey: Well, I’m glad you brought up those sequences, because those are some of my favorites. I’m a huge fan of noncoding RNAs [the RNAs that don’t go on to make proteins]. There are so many of them, and such a huge variety of them. And they work in so many important ways (SN: 4/13/19, p. 22).
I don’t think that 20 years ago we could have conceived that RNAs that didn’t make proteins would actually be important for something. The genes those RNAs were copied from were considered broken genes or pseudogenes. They were junk.
Green: Or sloppy transcription; that our enzymes are just going off and making a bunch of RNA because they don’t know how to control themselves. But, no. And I like your point about 20 years ago, we couldn’t imagine. I would propose that 20 years from now, we might look back at this conversation and say, “Oh, my goodness, think about all these other ways that the genome functions.” There’s no reason to think we have our hands around it all in terms of all the biological complexity of DNA; I’m quite sure we don’t.
Saey: And even when you find a protein-coding gene, you’re not just making one protein. You’re making, on average, seven or eight different versions of this protein from the same gene. After RNA gets copied from DNA, you can mix and match the little parts of a gene to make completely new proteins. And then you can tack on all of these other little chemical groups to change the way things work.
Green: When I was getting my Ph.D. at Washington University in the 1980s, I didn’t work on DNA, I didn’t work on molecular biology, I didn’t work on RNA. I was working on a set of proteins, studying how they had sugar molecules added to them after they were made, and how, depending upon what tissue they were made in, they got different structures of sugar molecules attached. So just as you point out, you start off with one gene, and you can end up with multiple RNAs that lead to multiple different proteins. And each of those proteins could have different modifications depending on what tissue, what conditions, what development stage, et cetera. This is the incredible amplification of complexity. It’s not in our gene number. We have a long way to go to fully understanding all this.
Saey: Another thing that really surprises people is how much of our genome is made of extinct viruses and transposons — transposons being these jumping genes that still hop around in our genome. Those transposons can occasionally cause problems, but we also got a lot of innovations from them, including the human placenta, and maybe some things about the way our brain works. So, we’re not even completely human. If you want to view it that way, we’re a lot virus.
Green: Right. We’re a lot virus. We’re also not all Homo sapiens. Many, many people carry Neandertal bits from a time when Neandertals and Homo sapiens coexisted, and actually interbred (SN: 5/8/21 & 5/22/21, p. 7). But not everybody in the world has that, which is also interesting. One of the aspects of genomics is that it not only has taught us and given us the biological instruction book, it’s also given us a fascinating record of evolution. We can use it to learn lots of things about our evolution, about human migrations, about aspects of humans on this globe.
Focus on diversity
Saey: Most people who are interacting with DNA and with the human genome these days do it through ancestry testing and consumer DNA testing. So you can identify the part of the world that people’s DNA came from. And that gets into a lot of discussion about race, and whether race has a biological basis, and what that might mean for medicine.
There’s been a lot of criticism lately of genetics and genomics, because it’s based a lot on the DNA of people of European ancestry — white people like you and me. But there’s a huge amount of genetic diversity in the world among humans, and especially in Africa, where humans got started. So what are we doing about getting a handle on the vast array of diversity that humans have?
Green: There’s no question that the successes in genomics that we’ve been discussing are worth talking about and worth showcasing. At the same time, as a field, we have not been perfect. One of the things that we just have to admit that we’ve really not been as successful on is making sure we’ve captured enough of the diversity of the human population with respect to the samples that we’ve used for doing genetic and genomic studies. We have got to fix this problem. It’s a very high priority.
I really want to emphasize, it’s not even just that it’s the socially right thing to do, that everybody should have information about their genomes. This is very important medically. If the only populations we have a lot of genomic data on are people of European descent, we limit our ability to move genomic analyses and eventually genomic medicine into populations that are not of European descent. And so there’s a high priority through a number of efforts around the world, including in the U.S., to work hard to capture much more diversity of the world’s populations in all studies that we do.
Saey: There’s been a lot of talk about racialized medicine, where you might have a person come in who is African American, and then you would say, “Oh, well, we should consider this to be the genome that we look at.” Is that a good approach to take? Or do you think it should be broader somehow?
Green: The truth is, of course, there are certain diseases that tend to cluster in certain populations of common ancestry. And many times those are represented by racial groups.
But racial grouping is really a social construct that has numerous imperfections. And so on the one hand, you can’t totally ignore some correlations that exist with certain diseases or certain responses to medications in certain groups. But it’s a very blunt tool to use. And we could do better. The way we could do this better is to track much more accurately to specific genomic features, as opposed to certain racial characteristics. So I think what we really want to pay attention to, and we will be doing this increasingly, is thinking about better ways of grouping and stratifying individuals and populations.
Diversity missed
Genome-wide association studies can uncover common genetic variants that might, for example, help explain an individual’s susceptibility to illness. As of January, participants in these studies were overwhelmingly European, leaving other groups underrepresented.
Ancestry of individuals in genome-wide association studies as of January 2022
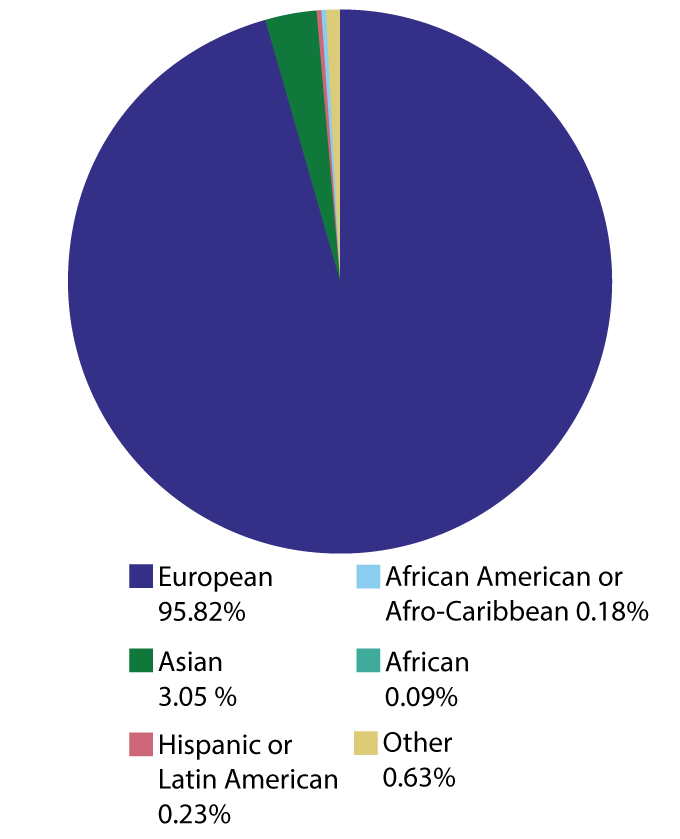
Saey: I wanted to touch too on what we mean when we say genetic diversity. For the most part I think people are familiar with what scientists call SNPs, single nucleotide polymorphisms, and what other people might refer to as mutations. But there are lots of other ways that you can have diversity in the genome: You can be missing entire genes or entire chunks of chromosomes or you can have duplications of certain genes. Are we now able to look at that type of diversity as well? And do we know if that’s important?
Green: There’s no question that all forms of genomic diversity — genomic variation is probably the word I would use — are not only biologically relevant, they’re proving to be medically relevant. Now, we don’t have a complete inventory of which ones are more relevant than others. But we already know of many examples where medically relevant variations in our genome can be a single letter, a string of letters, it could mean having extra letters or extra segments, or missing segments. It could be a rearrangement of segments. Every one of those [types of variations] are already known to be important in human disease, and eventually will be important for diagnostic medicine and the implementation of genomic medicine.
Saey: Do you envision a time when we will be able to study and interpret these bigger changes?
Green: I absolutely envision a time where people will get their complete genome sequenced end to end as part of their medical care, and maybe even at birth. I don’t think we’re there yet. But I truly believe that we will want that information as part of medical management. And I fully believe that technologies will become available and will be inexpensive enough to make it worthwhile. But those predictions are going to have to be based on evidence that indeed that’s feasible and valuable.
What’s next?
Saey: So where do we go from here? What does the National Human Genome Research Institute do now that researchers have generated end-to-end sequences of every human chromosome?
Green: We recently finished a two-and-a-half-year strategic planning process to ask that very question for this coming decade. It was actually an overwhelming exercise because there were so many good ideas. We published these in Nature — our 2020 strategic vision. Some of it [is] applications of genomics to medicine. Of course, everybody’s going to be excited about that. But there are many other forefronts of genomics that are just as exciting.
We still don’t have the perfect technologies that we can deploy anywhere in the world in any health setting, any medical study, that will get us end-to-end sequencing. We need better and cheaper technologies for letting us read human genome sequences inexpensively in clinical settings. We need complete end-to-end interpretation of every base of the human genome. We need to know not just about the genes, we need to know about all these noncoding regions. We need to understand every human variant that we can find in the world population. And we need to know: Is that variant biologically silent? Is it biologically relevant? Is it medically relevant? If it’s medically relevant, what’s the action that should be taken? That starts to point us to understanding the genomic basis of disease and also to think about how can we use information about genomic variation in the practice of medicine.
Also, we will continue to think about the implications of these genomic advances to society. How are we going to make sure people understand this? How are we going to make sure things are applied equitably? How are we going to make sure it doesn’t exacerbate inequities in our society? How are we going to deal with a whole host of issues related to privacy?

Saey: I’m glad that you brought up equity and privacy, because those are some of the things that people are most concerned about right now. There are a lot of historically marginalized people who don’t want any part of genetic research because of the way their groups have been treated in the past. There’s been this history of colonialism. These groups say, if we’re going to do genetics on our people, then it should be our people doing it for us. What is NHGRI doing to build capacity in these communities so that they can do their own research and, maybe, if they decide they want to, share that with other people?
Green: I completely agree with the notion that if genomics is going to be a successful field, especially as we move this into medicine, we have got to make sure that we engage people from all different communities, all definitions of diversity, and make sure they benefit from it. We absolutely emphasize this point repeatedly in our 2020 strategic vision, so much so that the very first thing we did in 2021 was to release what we call an action agenda for enhancing the diversity of the genomics workforce.
Another experience we’ve had at NIH that I think is very illustrative of this: We recognized that we wanted African scientists to get more involved in doing genomics. And through a program called H3Africa, the Human Heredity and Health in Africa program, that the NIH and the Wellcome Trust funded, the philosophical mantra is to empower African scientists to do all the studies and build capacity there. It’s been a success by almost any metric. But it’s exactly what you said: We want them to do the studies, we want them to engage with their local communities. We’ll never build the trust if we just come in and say, “We’re going to do all of this.”
Saey: In terms of privacy, you’ve said a couple of times that you could have somebody’s genome completely sequenced, and then their doctor can use it. But don’t we get into a situation that could be like the movie Gattaca? Some people could be discriminated against if they don’t have their genetic flaws fixed? Are you somehow creating a class of lesser people and more perfect people who don’t have the genetic flaws that everybody else has?
Green: You just laid out several major ethical dilemmas, and they’re all valid, and we could spend hours talking about each of them. What I would say about our field is, we’ve recognized that everything we are doing is a two-edged sword. On the one edge of that sword are these incredible opportunities for improving the practice of medicine. On the other edge of that sword, as with many technologies, it could be used in ways that would be societally unacceptable. It’s a reason why the field has from the beginning always embraced and invested in ethical, legal and social implications research, or ELSI research, which has attempted to anticipate these concerns and try to provide an evidence base to build policies, and in some cases, laws.
We do have in the United States a major act called the Genetic Information Nondiscrimination Act, which offers some protection against genetic discrimination. We have laws and policies that protect people’s medical information.

We should recognize that genomics is just part of a bigger set of societal issues, as more and more intimate information about us is electronically available. Trust me, we can learn a lot about you if we just reviewed your Visa card purchases. We as a society have to recognize that, yes, genomic information has some unique attributes, but it’s not totally exceptional. We need to be part of a broader framework for protecting people so that we can benefit from these incredible opportunities.
We just need to make sure we don’t get too far out over our skis. Just because we can do something, doesn’t mean we should. We need to think about all the consequences. We should be constantly understanding what will society tolerate, what do people not want. We have some things that are going to be completely unacceptable, like doing genetic editing in unborn children. At this stage, we simply don’t think that’s a smart thing to do, we’re not ready to do it, the scientific community has condemned doing it (SN: 12/22/18 & 1/5/19, p. 20).
Saey: I do want to circle back, because when we were talking about these noncoding sequences, a lot of them help control how genes are used. That may not be so obvious if you just get this string of somebody’s DNA letters. Can you tell from that how those genes will be used? And how those things will be put together? Or is that something you cannot tell by looking at DNA?
Green: There’s no question that sometimes when you talk about genomics, and you talk about genetics, and you focus on the genes — you sometimes see the tree and you lose track of the forest. The forest is medical complexity and biological complexity. And for most things about ourselves, how tall we are, what we look like, and common diseases — hypertension, diabetes, Alzheimer’s, autism, et cetera — things are much more complicated than looking even for one gene. It’s multiple genes. And it’s almost always a greater choreography with our lifestyle, and our social experiences, and our exposures and everything from diet to exercise. There’s a lot more to health and disease than just our genes.
The grand challenge in many ways for the coming decade or two is doing these very large-scale studies where we have as much data as possible, not just genomic data, but lifestyle data and electronic health record data, and environmental data and physiological data. There are absolutely going to be patterns. And we’ve just got to find those patterns.
Saey: We’re almost out of time. It’s been wonderful talking with you. Did we miss anything?
Green: We missed all sorts of wonderful things, but you can only spend so much time walking down memory lane.
What I would say in closing are two things people need to remember: First of all, how incredibly exciting this field is, and how incredibly eager we are to build our tent with more and more people from all different disciplines. And we also want people of all different populations and ancestral groups from all parts of the world. It’s going to be so important to do that.
The reason we want all these people involved is, we just touched on so many things that we still don’t understand. We need creativity. And we don’t have a playbook. Just like those days where we were bewildered of how we were going to get the Human Genome Project really done, I don’t really know how we’re going to get complete end-to-end understanding of the human genome. But I know if we get creative people working on it, we’ll make incredible progress.
February 09, 2022 at 09:26PM